-
How to dynamically copy specific tables from source systems with Azure data factory
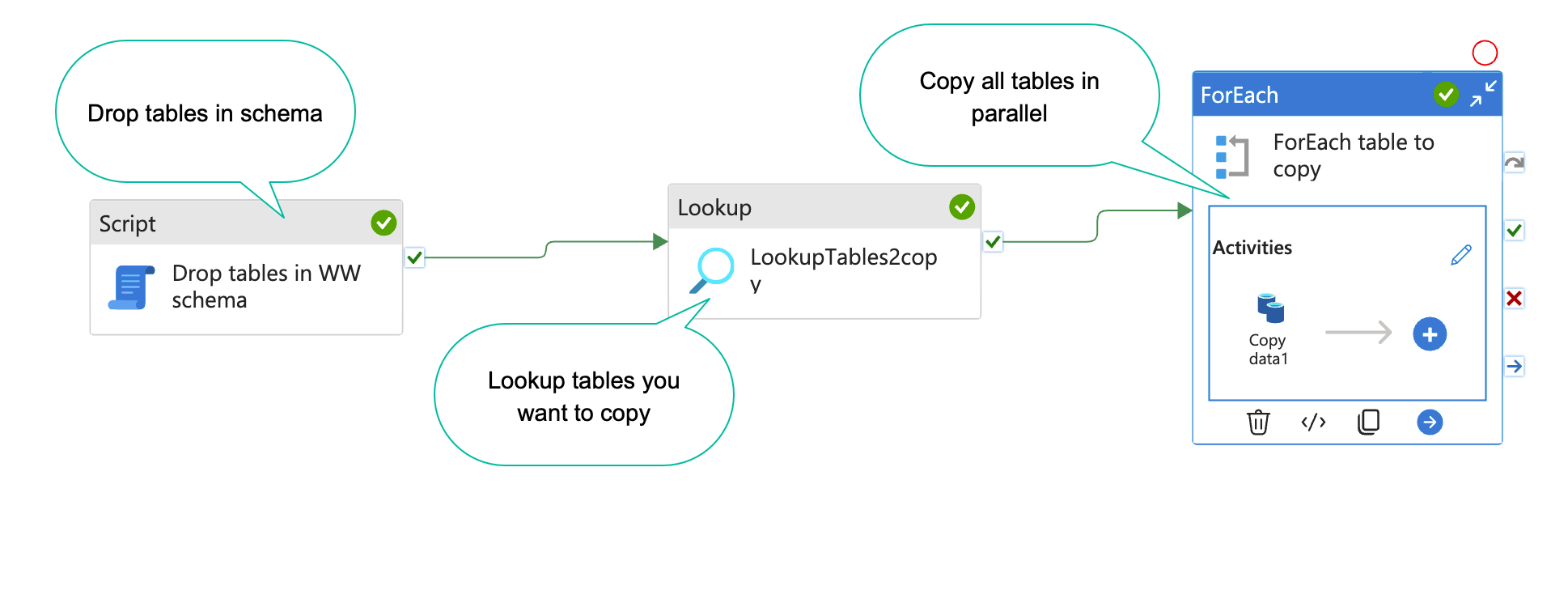
When you are working on a data project, you often have a list of tables you want to copy to your DWH database or staging database. With Azure data factory(ADF), this is easy to set up(Kind of). In this blog post, I will show you how. The result will end up looking something like the… Continue reading
-
Guide: Setup data factory to run locally
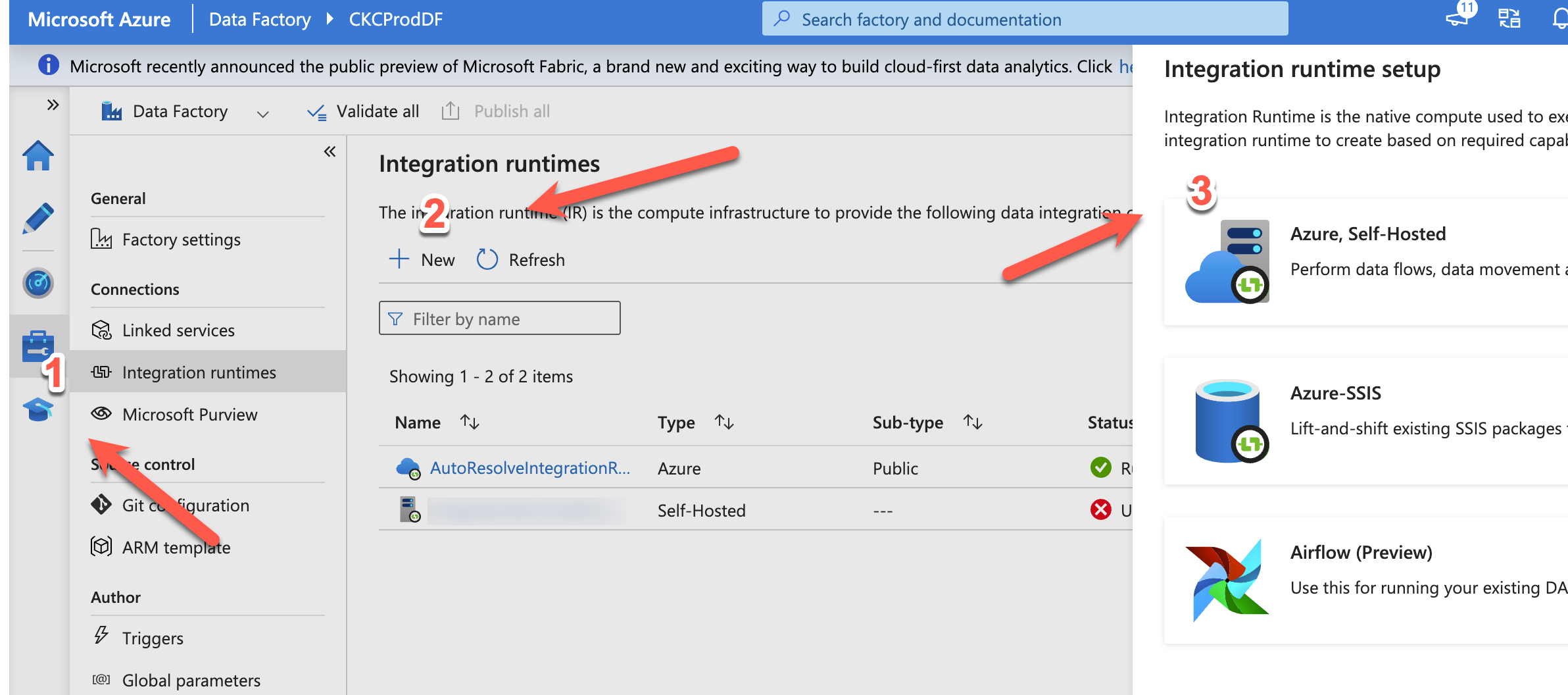
Azure Data Factory (ADF) is Microsofts cloud based ETL tool. It is in many ways, better than their old on-premise ETL tool “integration services”. Luckily, you can easily set up ADF to move data around on-premise. In this blog post, I will show you how 🙂 I will assume you already have an ADF running,… Continue reading
-
Refresh a Power BI dataset from data factory
When I have my data model in my Power BI dataset, there are several reasons, I want to update it when I am done with my ETL. Among others: So in this blog post, I will show how to do it from data factory (ADF). It is a lot of steps, and I will assume… Continue reading
