-
Power BI in developer mode with git integration between desktops and workspaces
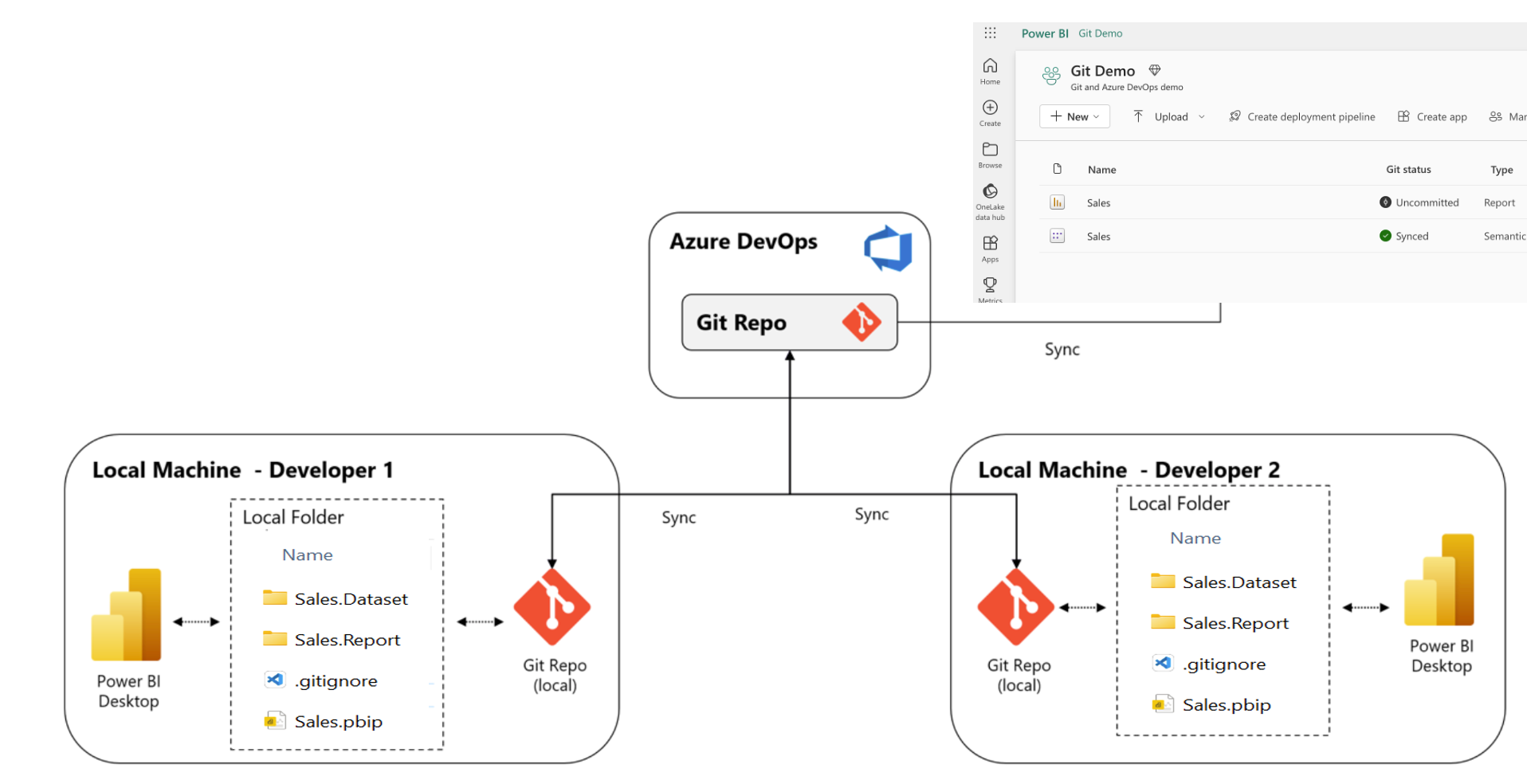
Introduction Source control in the Microsoft BI and datastack have always been a little hard to do. It was hard in the old days, with SSIS and SSAS, and it is also hard with Power BI. To name a few obstacles: There is of course also some major downsides with not using source control systems… Continue reading
-
How to dynamically copy specific tables from source systems with Azure data factory
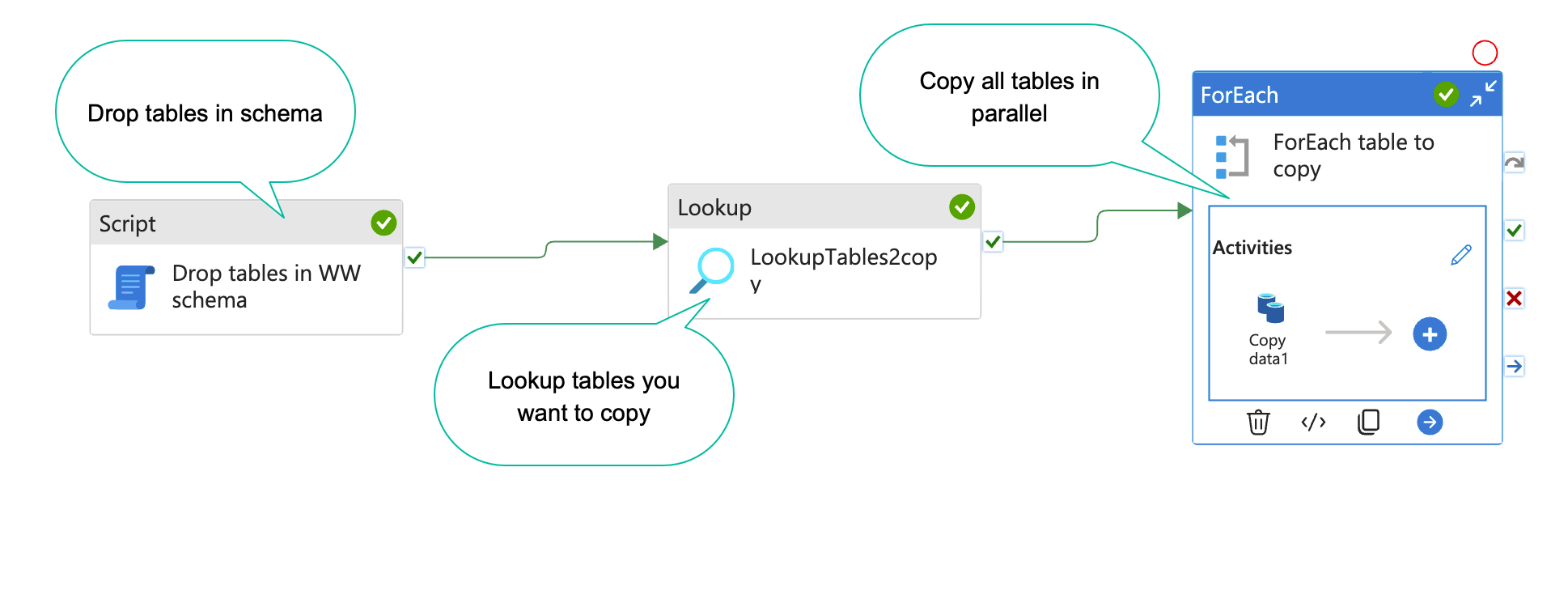
When you are working on a data project, you often have a list of tables you want to copy to your DWH database or staging database. With Azure data factory(ADF), this is easy to set up(Kind of). In this blog post, I will show you how. The result will end up looking something like the… Continue reading
-
Guide: Setup data factory to run locally
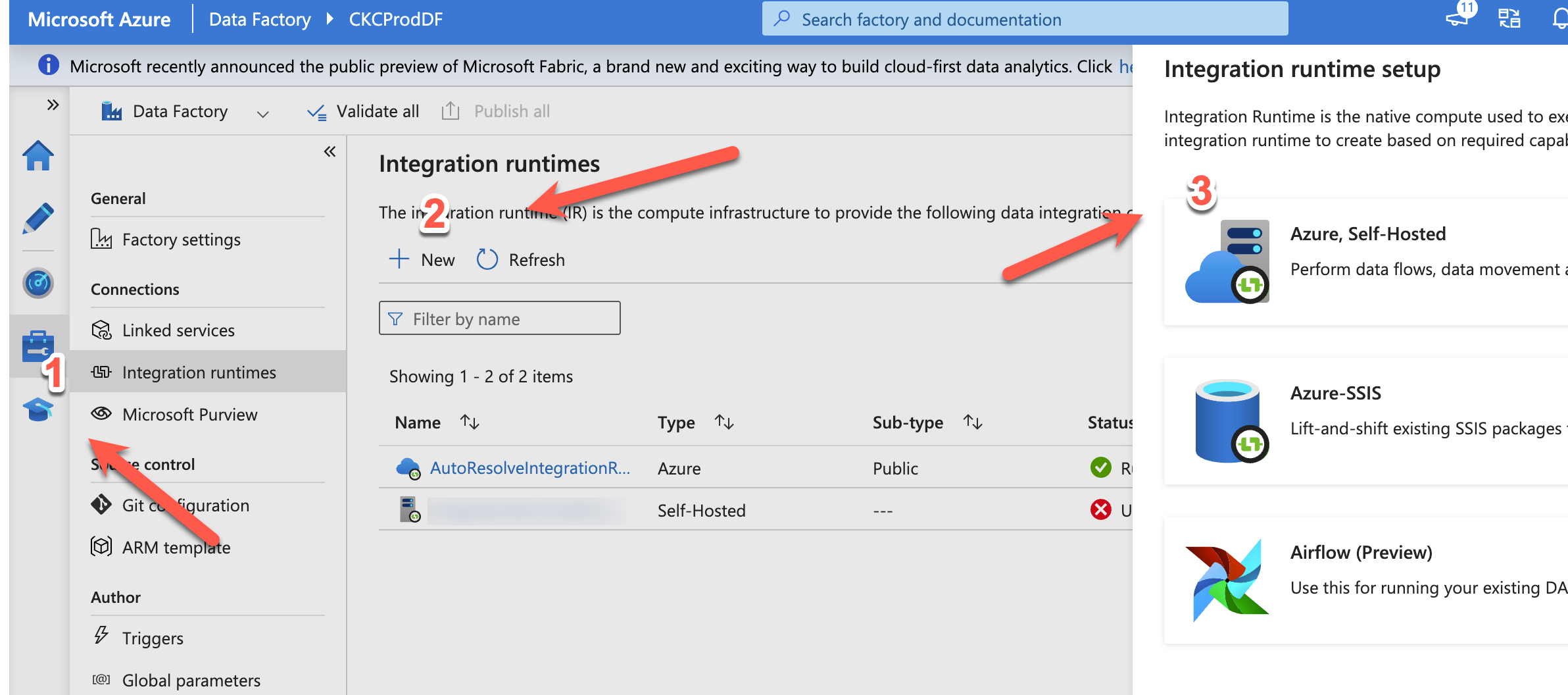
Azure Data Factory (ADF) is Microsofts cloud based ETL tool. It is in many ways, better than their old on-premise ETL tool “integration services”. Luckily, you can easily set up ADF to move data around on-premise. In this blog post, I will show you how 🙂 I will assume you already have an ADF running,… Continue reading
-
Refresh a Power BI dataset from data factory
When I have my data model in my Power BI dataset, there are several reasons, I want to update it when I am done with my ETL. Among others: So in this blog post, I will show how to do it from data factory (ADF). It is a lot of steps, and I will assume… Continue reading
-
How to scale your azure sql database with SQL
An Azure sql database is super easy and cheap to setup and use. However, if you want to do some serious data manipulation, you will find the cheapest versions are to slow to use, and every upgrade you make on the sql database, is a doubling in price. If you are a data engineer, like… Continue reading
-
How to create sql azure login and user
I use sql azure databases a lot. Both as backend, datamarts and also for data exchange layer with 3. parties. For that, I need to create users fast and easy. There is no interface for doing that in SQL azure, so you have to do it with SQL. Step 1: Connect to sql with manegement… Continue reading
-
Doing Windows development on my android tablet with Azure
The scenario: So, I’m on the run, to a family party, a boring meeting, or something similar 🙂 Suddenly, I get this great idea for the BI project I’m working on. I didn’t bring my monster laptop, because it is to heavy & ugly. Instead I’m sitting with my android tablet. What to do now???… Continue reading
