-
Tip of the day 🙂 How to change the font size in your result grid in SSMS
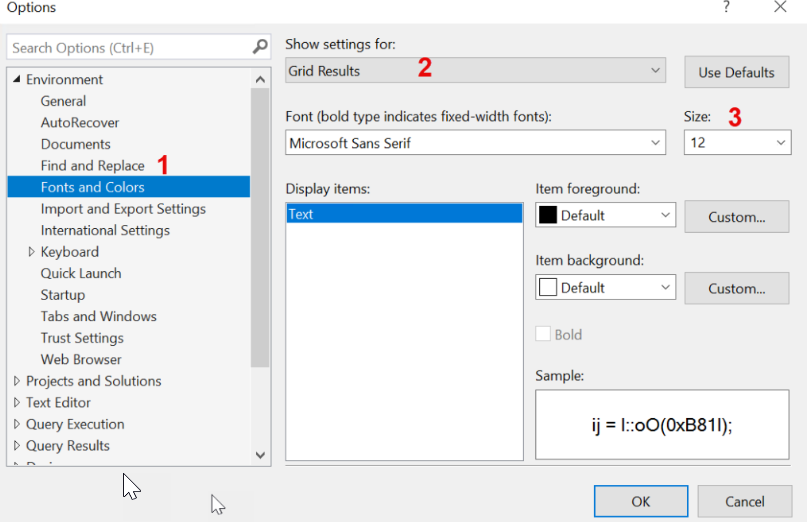
Just a nice litlte tip, so I can remember it myself if I need to change it again at some point 🙂 When you are presenting or sharing your screen with others, and they have another resolution than you, it can be hard to see the small things on the screen. In SQL Server Management… Continue reading
-
How to dynamically copy specific tables from source systems with Azure data factory
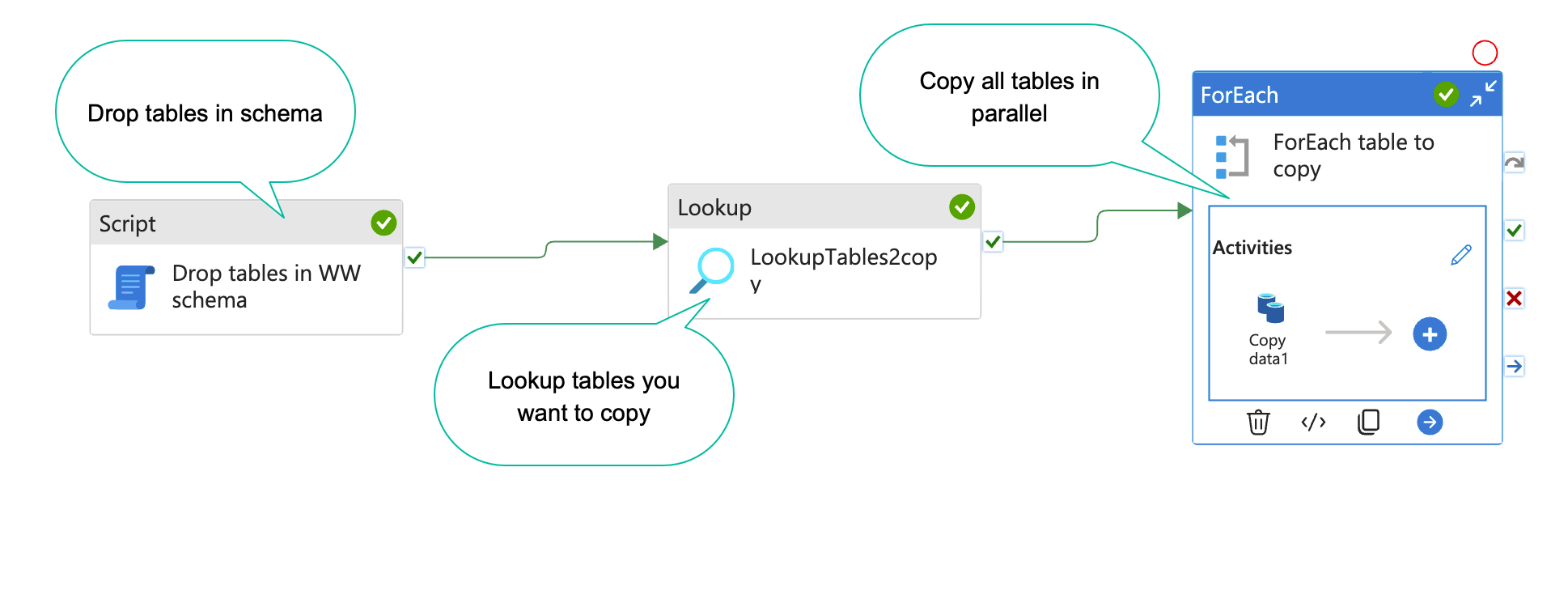
When you are working on a data project, you often have a list of tables you want to copy to your DWH database or staging database. With Azure data factory(ADF), this is easy to set up(Kind of). In this blog post, I will show you how. The result will end up looking something like the… Continue reading
-
How to scale your azure sql database with SQL
An Azure sql database is super easy and cheap to setup and use. However, if you want to do some serious data manipulation, you will find the cheapest versions are to slow to use, and every upgrade you make on the sql database, is a doubling in price. If you are a data engineer, like… Continue reading
-
How to create sql azure login and user
I use sql azure databases a lot. Both as backend, datamarts and also for data exchange layer with 3. parties. For that, I need to create users fast and easy. There is no interface for doing that in SQL azure, so you have to do it with SQL. Step 1: Connect to sql with manegement… Continue reading
