
SQL server 2012 comes with a new set of window functions and analytically possibilities, which I will look into in this blog post.
Prior to 2012
Prior to the 2012 version, windows functions were also possible. The syntax looked like this:
Ranking Window Functions
< OVER_CLAUSE > :: =
OVER ( [ PARTITION BY value_expression , … [ n ] ]
<ORDER BY_Clause> )Aggregate Window Functions
< OVER_CLAUSE > :: =
OVER ( [ PARTITION BY value_expression , … [ n ] ] )
Where the over clause creates a window for the entire result set, and the PARTITION BY divide the window to a lot of smaller distinct windows. This can be used, when you look at a row with a value, for instance, to a product and day, and you want to compare it to the value for the same product to month or year.
To demonstrate both the new and old version I’ll introduce a dataset.
Let’s look at the Vestas share prices. I’ll create a table only with the share prices for Vestas, like so
CREATE TABLE [dbo].[Stock]
(
[StockID] [int] IDENTITY(1,1) NOT NULL,
[Name] [nvarchar](50) NULL,
[Date] [datetime] NULL,
[OpeningPrice] [money] NULL,
[High] [money] NULL,
[Low] [money] NULL,
[Last] [money] NULL,
[Volume] [float] NULL
)
Then I import the data for the last couple of years from http://www.euroinvestor.dk/. Now we have a realistic dataset.
Let’s look at the closing price for the last 100 days like this:
SELECT top 100 StockID, Name, Date, last
FROM dbo.Stock
ORDER BY Date Desc
This yield the result

Using the window functions prior to the 2012 version, we could use the window functions like this
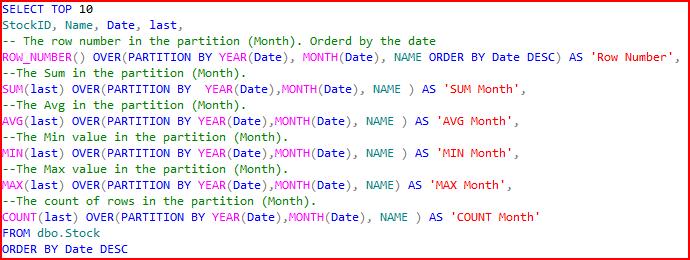
Giving this result set
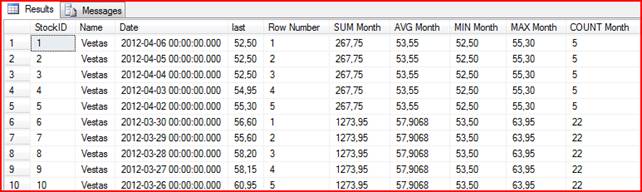
You can use these values to do more intensive analytics etc.
Of course, the aggregate functions could also be achieved with a subselect, or a join to the same SQL statement grouped on the same as it is partitioned by in window functions, but this would for obvious reasons perform worse and yield a more complicated SQL.
The aggregate functions also provide the same as what will be performed by analysis services, when you are build a data mart with aggregated values.
The Row number is often used in data collection scenarios where you want to filter out duplicates.
The 2012 version
So, that is how window functions worked prior to the 2012 edition. So lets look at some of the things they have improved. First of all, the syntax has been extended as shown below:
OVER (
[ <PARTITION BY clause> ]
[ <ORDER BY clause> ]
[ <ROW or RANGE clause> ]
)<PARTITION BY clause> ::=
PARTITION BY value_expression , … [ n ]<ORDER BY clause> ::=
ORDER BY order_by_expression
[ COLLATE collation_name ]
[ ASC | DESC ]
[ ,…n ]<ROW or RANGE clause> ::=
{ ROWS | RANGE } <window frame extent><window frame extent> ::=
{ <window frame preceding>
| <window frame between>
}<window frame between> ::=
BETWEEN <window frame bound> AND <window frame bound><window frame bound> ::=
{ <window frame preceding>
| <window frame following>
}<window frame preceding> ::=
{
UNBOUNDED PRECEDING
| <unsigned_value_specification> PRECEDING
| CURRENT ROW
}<window frame following> ::=
{
UNBOUNDED FOLLOWING
| <unsigned_value_specification> FOLLOWING
| CURRENT ROW
}<unsigned value specification> ::=
{ <unsigned integer literal> }
As you may have noticed, one of the short comings prior to the 2012 version is that you can’t add an ‘order by’ to the aggregate functions, hence you can’t calculate a running AVG or SUM. That has been changed in the new version. Let’s try to add an order by to the previous SQL. And let’s just delete the collumns that makes no sense. So the SQL will look like so:

Then we have a running AVG in each month.

All of my examples probably don’t make much sense to a stock broker. I’m only looking at the SQL functions, and not the data. One thing I do know, is however, that the running AVG won’t make much sense, starting all over from the first each month. Luckily there has also been added a sliding window function, so we can look at the previous/next n rows when doing our calculations.
This can now be done like so.

Where the AVG now is the AVG of the current row, and the 2 previous rows. The extension of the ORDER BY, now overrides the default partitioning. The result set:

Conclusion
I have looked into some of the new window functions, and it is safe to say, that they have been significantly improved, and can now be used to do more advanced analytics in a simpler way.
A new addition to the window functions is also some new analytic functions that can be used. This is: CUME_DIST, LEAD, FIRST_VALUE, PERCENTILE_CONT, LAG, PERCENTILE_DISC, LAST_VALUE, PERCENT_RANK.
I’ll cover those in the next blog post.
Leave a Reply